Most industrial businesses produce large volumes of time-series big data. Operational data comes in many different forms and can require different treatments to be useful. Organisation’s also have many other sources of data, such as financial data, SCADA or ERP data.
As businesses become more astute to the value of their data, there is a push to use machine learning and advanced analytics to acquire valuable business insights. While this is a fantastic step towards digital transformation, there are a few issues that can limit the efficiencies and benefits of advanced analytics and machine learning.
Many organisations, encounter similar issues:
If organizations uncover these issues when they commence machine learning, it is often the case of the cart going before the horse. Before you start implementing digital transformation in the form of artificial intelligence and machine learning, you first need to have the right data available in the right format.
What’s actually needed is a data storage strategy and solution.
What is the difference between these common terms and what are the critical elements to consider when selecting a data storage solution?
Traditional process data historian’s store historical information about a process or manufacturing system, usually this data comes directly from PLCs, DCS or other process control systems, with some data being able to be entered manually. This data can be used for condition monitoring, and to diagnose the causes of asset reliability issues. Data is often analyzed and visualized in a separate software.
Traditional process historians tend to have a complex infrastructure, which means getting data out of the historian can become difficult. Due to licensing and volume restrictions many data historians aren’t set up to store all sensor data, and as the traditional process historian does not store other organizational data it is not a complete repository of an organisation’s data.
Data Warehouses have the capability to store big data, combining data from multiple, varied sources (including process historians, or directly from PLCs, DCs systems, along with ERPs, CMMS, APM, DCS, ICSS, SCADA, financial systems, transactional systems) into one easily manipulated, comprehensive database. Becoming a complete repository of an organisation’s information. The data can be organized and analyzed by separate visualization software to determine trends and can be easily reported on by end users.
Data Lakes store structured, unstructured and semi structured data in an unorganized, unclassified repository. The data is often not cleansed, deduplicated or corrected and it can be hard to uncover business insights without extensive time spent data wrangling. Data lakes have acquired the nickname data swamp due to the unorganized nature of the data storage. Data Lakes are typically used by data scientists, rather than cross-organizational users.
To fully utilize an organization’s data, it makes sense to consolidate all data sources into one scalable location. This increases the efficiency in which a company can access their complete data history, conduct analysis, and make business decisions. As such, we recommend a data warehouse as a complete repository of a company’s data.
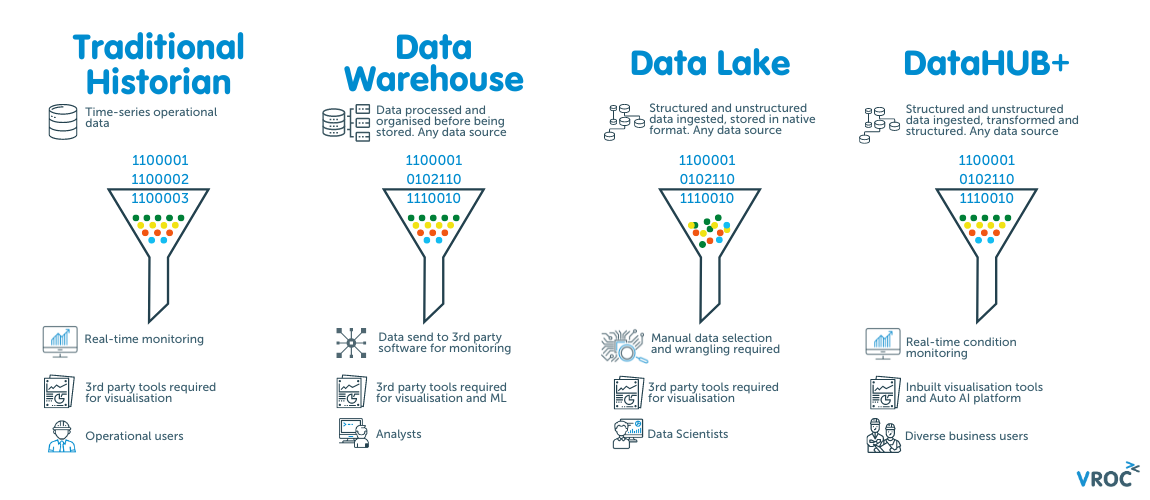
VROC’s platform DATAHUB+ combines the benefits of both a Data Historian (with its real time condition monitoring) and a Data Warehouse (single source of truth) in one. DataHUB+ accepts data from any source, which can be structured, unstructured and semi-structured (like a data lake). Rather than storing this data in an unorganized way, DataHUB+ transforms the unstructured data into structured data for warehousing, becoming your single source of truth. It’s inbuilt analytics and visualizations tools mean no other software is required to perform analysis and build visualization from your big data. Meaning data insights just a couple of clicks away! Learn about data collection and architecture.
Unlike other Data Warehouses, the tools for processing data reside in DataHUB+, so there’s no requirement to repeatedly copy data to work with it. This allows users to handle much larger data sets, without needing to download to local machines which are often limited by computing power.
As we can’t presume from the outset to know all the potential ways that the data can be used, the data is available for use with exploration and visualization tools which can query across all the data. With this approach, it’s even possible to join finance, production, and OH&S data to gain new and intriguing insights, possibly for ESG insights or the optimization of complex processes.
Just like a traditional process or time-series data historian, DataHUB+ allows operational teams to monitor their processes and equipment in real-time. Teams can set up dashboards to monitor status, plot trends and performance, which is refreshed as new data is ingested. Teams can factor in known thresholds, and create band limits for operating envelopes on sensors, which can trigger alerts and predictive maintenance activities. The added benefit is that additional data that exists in DataHUB+, which can be immediately used in analysis.
Right, the ultimate objective! Advancing digital transformation and improving business outcomes with machine learning and artificial intelligence. After collating data from systems across the organization into a scalable storage solution, data experts can use machine learning and AI tools to build models. Most data warehouses will integrate with data science tools.
DataHUB+’s sister product OPUS, allows organizations to develop models and deploy them straight into production – operationalizing AI for real time insights. Models are produced without any coding and in the one interface, meaning a wider cohort can model their own problem statements, processes and business queries, no longer limiting this work to data science personnel.
The benefits of machine learning can be numerous and diverse once there is a scalable and robust data storage solution in place. Getting this data solution in place is the first critical step in a company’s digital transformation journey.
Get in touch with our team if you need assistance with your time-series data storage.
Learn how no-code AI and AutoML help industrial teams scale predictive maintenance, root cause analysis, and reliability insights across critical assets.
Read ArticleThree early signs of equipment degradation that Reliability Engineers often miss
Read Article