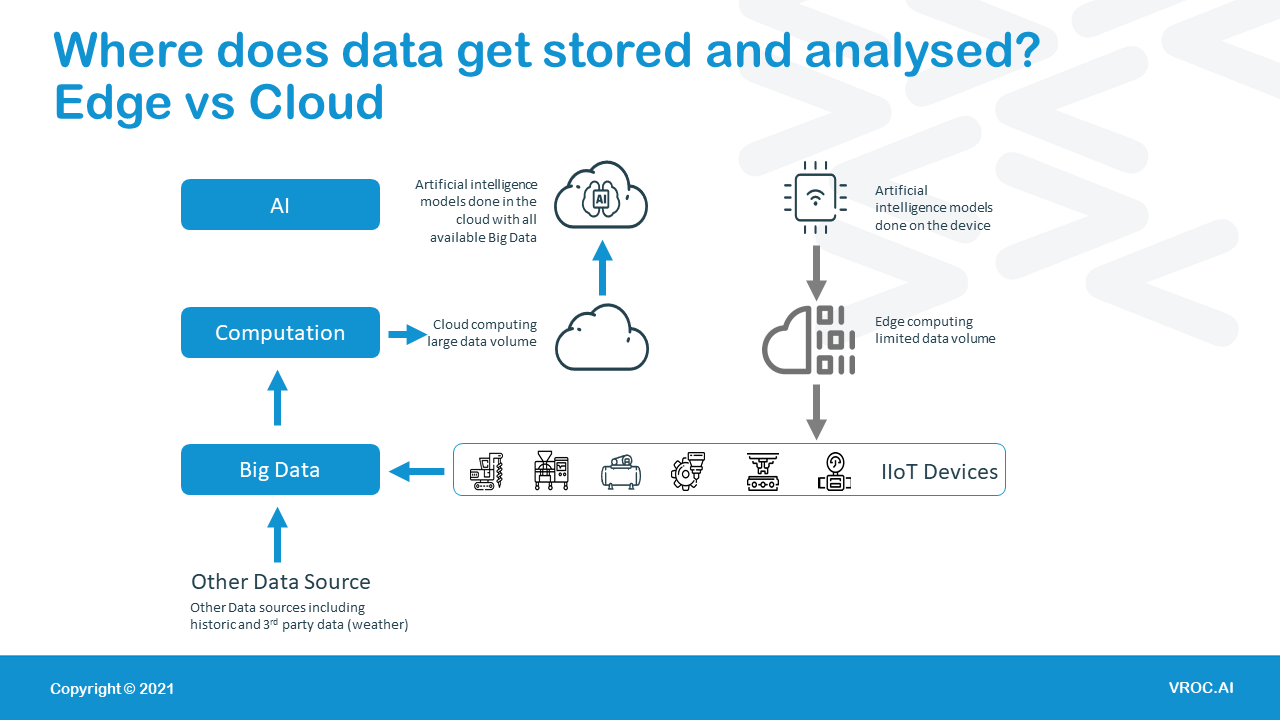
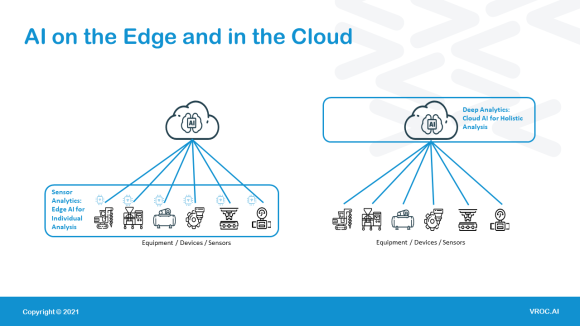
The main difference between cloud and edge is the volume of data that can be processed, the latency and therefore the depth and scope of the analytics able to be conducted.
Learn how no-code AI and AutoML help industrial teams scale predictive maintenance, root cause analysis, and reliability insights across critical assets.
Read ArticleThree early signs of equipment degradation that Reliability Engineers often miss
Read Article